joynuelle.github.io-cs639
View the Project on GitHub joynuelle/joynuelle.github.io-cs639
Selecting Aesthetically Best Photos
CS 639: Computer Vision Final Project
Joy Nuelle - email: nuelle@wisc.edu
Julia Kroll - email: jkroll3@wisc.edu
Our slides - https://docs.google.com/presentation/d/1lciKNwqGwnrzZFNALEH2i6eHCInVTmboA9VXBjecoKQ/edit?usp=sharing
Proposal:
With the rising popularity of smartphones over the past ten years, millions of users all over the world have had access to photography and the ability to capture billions of photos. It’s common to take multiple photos of the same scene, and when going back to delete some, either to clear up space or to simply choose the “aesthetically best” one to post on social media, this process can be difficult and time-consuming. The problem we are trying to solve is to first, define and continue doing research on what makes a photo aesthetically good, and second, create algorithms based on our research to help the average person decide when to keep or discard a photo, given multiples of a similar scene. Oftentimes, similar photos have subtle differences in colors, composition, contrast, lighting, etc, and our goal is to investigate the best combination of photograph features that contribute the most to a photograph’s aesthetic quality.
Our research topic is important in both practical and research terms. On the practical side, by choosing the best image out of each set of similar photos, we can avoid wasting device space occupied by near-duplicates of an image, and also eliminate the time-consuming nature of individuals each reviewing hundreds or thousands of their photos. On the research side, we are interested in exploring this topic because there is currently a lot of debate in the computer vision research community around how to algorithmically assess the subjective human perception of what makes an aesthetic photo, and how to select features that correspond to people’s emotional reaction to an image.
Several related consumer-facing apps have been released over the past five years or so. Many of these have been discontinued, but they were marketed as a way to automatically analyze users’ smartphone photos and rate their photo quality (EyeEm), group similar photos and weed out bad captures (Gallery Doctor), or select and aggregate users’ “best” photos based on the number of times a person appears in a set of photos (Google Photos).
We also found several patents from 2013-2014 which pertain to detecting and selecting best photographs (Sutherland et al, 2014), assessing aesthetic quality of photographs (Obrador et al, 2014), and predicting the aesthetic value of an image (Grenoble et al, 2013).
In the academic research, methods tend to focus on color harmony and image composition or cropping, but there is extensive debate and contradicting opinions on the best method of feature selection, and whether to focus on high-level perceptual features related to photographic principles or lower-level features. Different research teams have chosen different features, devised algorithms to curate signatures of photos that could quantify aesthetic quality, and then compared the signatures to human judgments. Researchers suggested several different applications for these techniques, such as selecting content for web image search results (Ke et al, 2006), professional headshot selection (Aydın et al, 2015), and as automated alternatives to professional photography editing (Deng et al, 2018).
We plan to explore new approaches based on the current research that we have reviewed. Because there isn’t a single established algorithm that best captures aesthetic image quality, we plan to continue in the same vein as current research, by refining and combining past techniques to search for feature definitions that improve upon past methods and yield competitive results compared against human judgments.
Quantifying images’ aesthetic quality is an extremely difficult task since human judgment of aesthetics is subjective. Therefore, existing approaches aren’t all-inclusive, and there are many features to test and analyze. Based on past research, our solution may be a combination of several different approaches and techniques, leading us to achieve a more nuanced conception of which combination of features succeed at representing aesthetic image quality.
We can evaluate the performance of our solution against human judgments of aesthetically best photos, as well as published performance of past algorithms against specific datasets.
First we will identify a variety of features to use in our aesthetic signature definitions. Then we will select datasets to apply these signatures to, and generate ratings of aesthetic image quality. We will compare these ratings to results of past publications, labeled datasets with human judgments, and/or new human judgments, when possible.
One potential extension of our research is combining multiple similar images to generate a new aesthetically superior image, which would be a new approach. Enhancing images through methods besides color and cropping (such as combining facial features of the same subject from multiple images to create an optimal portrait) is also new. Papers on image enhancement generally focus on altering individual photos by adjusting colors and cropping. Research has covered enhancing existing photos as well as systems to advise photographers in real-time while photographing a subject. One particular benefit of this new image-combining approach in image enhancement is that humans can manually crop and recolor images with a few clicks of basic software, but without advanced photo-editing knowledge, humans can’t combine elements from multiple images.
Approximate Timeline:
- October 7: Selected features
- October 13: HW 2 due (official deadline)
- October 16: Selected datasets
- October 27: HW 3 due (official deadline)
- October 30: Extracted first feature from datasets
- November 3: Midterm project report (official deadline)
- November 19: HW 4 due (official deadline)
- November 23: Extracted all features from datasets
- December 1: Evaluated performance against existing research and human judgments
- December 3: HW5 due (official deadline)
- December 8: Class presentation (official deadline)
- December 10: Completed final project (official deadline)
Midterm Project Report:
Progress
We selected some preliminary images for testing as we implemented our features. We created seven datasets of celebrity portraits at events they attended. Each dataset contains about 10-25 images of one person in the same outfit, same day, and same event, but with different poses, composition, lighting, and background. These photos were sourced from online image searches.
So far, we have implemented our first two features, out of five total. We took a divide-and-conquer approach, and Julia took lightness while Joy took blur. Both features were successfully implemented and give results computed across a single dataset.
Lightness
This feature is the average pixel value across all color channels, yielding an integer in range [0, 255]. The result is the same whether averaging across color channels, or converting to grayscale and then taking the average grayscale pixel value.
Below is an example of the results found from calculating the lightest, median, and darkest images across a dataset:

Perceived Lightness
In addition to lightness, we implemented perceived lightness, which takes into account human perception of different colors. This is calculated by taking the average pixel value across all color channels, but scaled and gamma-decoded for human perception. It yields a decimal value in range [0,1]. We consulted this post among other resources.
In order to calculate the value, first divide the color image by 255 to scale each pixel into range [0,1]. Then raise the scaled matrix to the power of 2.2, for gamma decoding (see gamma correction, source 1, source 2). Finally, multiply each color channel by its appropriate scaled value based on humans’ perception of that color. Humans are most sensitive to green (0.7152), medium to red (0.2126), and least to blue (0.0722) (see relative luminance, source).
The results are similar to basic lightness, but perceived lightness does yield a different lightest image on the same dataset:

Blur
By using the imgradient function to get the image gradient of a grayscale image, we sorted the values to identify the top values, and saved the median of those top values to calculate how blurry a photo is (see this post). Then we saved the max and min values within the set and displayed those so we could visually compare how blurry and sharp the photos were. Below is an example of the sharpest and blurriest images within one dataset:
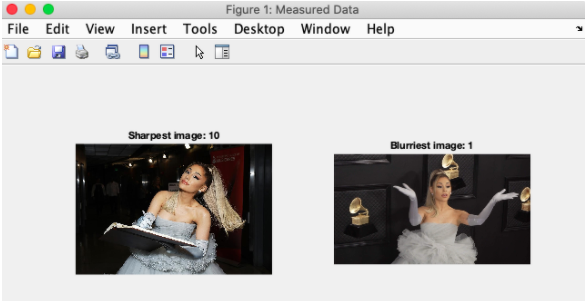
Challenges, revisions, and going forward
We are on schedule! No revisions are needed for our project scope or timeline.
In testing our first feature implementations, we discovered that our celebrity datasets have a great deal of variability in size and resolution, which doesn’t align with our use case to compare across images taken in a similar time and environment. We will standardize image resolution within each dataset as much as possible. We can also easily take our own cell phone photos for sets of images that are even more consistent in size, lighting, setting, etc.
We have three more features to implement: hue count, facial expression of eyes open versus closed, and the rule of thirds. We plan on implementing hue count as answered in this post, facial expression using CascadeObjectDetector (the cascade object detector uses the Viola-Jones algorithm to detect people’s faces, noses, eyes, mouth, or upper body), and rule of thirds by dividing the photo into a 3x3 grid and using face detection to determine whether the face is covering the points of intersection of the image grid.
Our plan is to each implement one more feature in the next week or two (by 11/11 at the latest), and have all five features implemented by our originally planned deadline of 11/23.
Evaluation
For each dataset, we will rank its images across all five of our features. For a dataset containing N images, the rank is range [1,N], where 1 is best and N is worst. For some features, there is a descending order, such as ranking images from least to most blurry. For other features, the median may be best, such as the image with median lightness that is neither too light nor too dark, but “just right.” Eyes open will be a boolean yes/no, boosting the overall rank of the image if it is yes. We still need to determine how we will quantify rule of thirds. Roughly, we will try to measure how close the face in the image is to the points of intersection when dividing the image up into a 3x3 grid and give it a ranking based on that measurement.
Once we have a rank for each image and feature, we will average the feature ranks per image and select the image with the best average rank. For instance, in a simplified dataset with two images, if one image gets feature ranks [1,1,1,2,2] and the other gets ranks [2,2,2,1,1], then the first image has an average rank of 1.4 and the second has an average rank of 1.6, meaning we conclude that our algorithm judges that the first image is the aesthetically best image of the two.
In further work, we could investigate a more sophisticated weighting system across features. Perhaps certain features are more important contributors to a good image, so those can be weighted more heavily in selecting the best image within a dataset.
We will also have several humans judge the aesthetic quality of images in each dataset, and compare the algorithm’s rankings to the humans’ rankings.
Post-Midterm/Final Update
Continued Features: Eyes Open
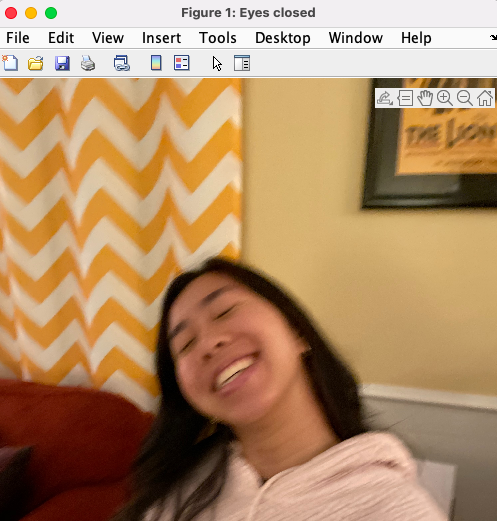
We used vision.CascadeObjectDetector to locate the face in the image, and then detected the eyes within the face, using the region of interest(ROI) as the face that the detector found first. The default CascadeObjectDetector is pre-trained and applies the Viola-Jones algorithm to detect people’s faces, noses, eyes, mouth, or upper body. We used ‘EyePairBig’ to detect eyes because for our datasets, we used portraits and the eyes were assumed to be a big part of the photo. If the detectors found multiple eyes or faces, it would save the biggest face as the one we would look at to see if there were eyes in that region. Likewise, it would use the biggest set of eyes that were found in order to compute whether or not those eyes were in the dimensions of the face that was found. It did a good job detecting whether or not there were eyes in the photo, but didn’t do a good job at detecting whether the eyes were actually open or closed.

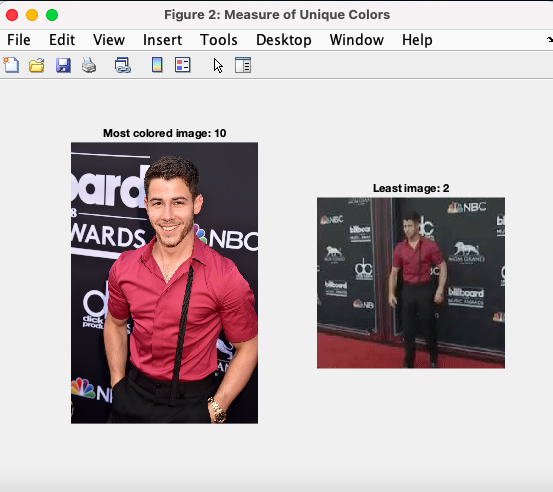
Hue count
To detect the image with the greatest number of unique colors, we reshape the image and then use unique to return the image’s unique colors in an array. The idea for this feature is to take the image that returned the most unique colors, because if there aren’t as many unique colors, it could either be too dark or too light, and we want to have diverse colors in the photo to represent highlights and lowlights/shadows.
Rule of Thirds
To calculate Rule of Thirds, we implemented an algorithm that executes the following steps. First divide the image’s height and width by three to get the location of lines on the 3x3 grid. Then use vision.CascadeObjectDetector() to find the bounding box for the subject’s face. If there happens to be multiple boxes/faces detected, use the largest box, assuming that the largest face is closest to the photographer and therefore most likely to be the intended subject.
The CascadeObjectDetector defaults to the FrontalFaceCART classification model, but if a frontal face is not found, then see if a profile face can be detected using the ProfileFace model.
Once the grid and face have been located, see if the face’s bounding box overlaps with one of the four intersection points. If there is an overlap, that means the image meets the rule of thirds principle. Otherwise, it does not.
For example, the image below does not meet our rule of thirds criteria because the face’s bounding box does not overlap one of the points of intersection on the image:

Algorithm and Results
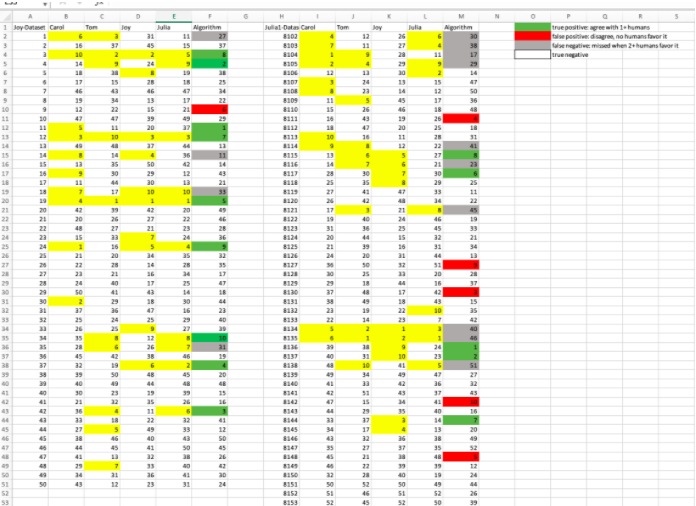
In analyzing the results(click here to download .xlsx file), we highlighted all the human rankings for both photo sets that were in a person’s top 10 choices (ranked from 1-10). Then, we found the algorithm’s rankings of photos 1-10 and color-coded the algorithm column based on how many humans did or did not agree with it.
For the indoor images, which had more similar backgrounds and varied more in blurriness, eyes open or closed, and rule of thirds, the algorithm did decent with only one false positive, where no humans favored image #10 when the algorithm ranked it #6.
For the outside dataset, our algorithm didn’t do as well and had more varying factors, such as how much light was in the image. It chose 5 images that no humans agreed with to be in the top 10, and also had 9 images that could have made it into the top 10, but it missed.
Problems Encountered, and Potential Solutions For Improvement
One problem we encountered multiple times was our feature calculation for eyes open or closed. The Viola-Jones algorithm was useful for calculating whether or not there were a pair of eyes in the photo, but it was not tailored to detect whether eyes were open or closed. Therefore, our algorithm was less accurate because it would sometimes find eyes that were closed and return true for eyes open/closed, giving the image a boost above others in the rankings. If we had more time, we would try to develop a more sophisticated algorithm to better detect if the eyes that the Viola-Jones’ algorithm returned were open or not. Another issue we encountered was the blur measurement in the outdoor photos. Our blur feature implementation would actually pick up clouds as being “blurry”, and preferred the photos where the sun came in sharply because there was no “blurry sky” to see. Whereas when we were indoors, blur was analyzed more accurately. As a future improvement, we could allow the user to choose the least blurred photo and then compare the other photos to that one photo that the user provided, giving us a more accurate calculation.
Conclusion
In conclusion, we were able to compute two high-level features (rule of thirds, eyes open) and three low-level features (blur, hue count, perceived lightness) in order to rank the aesthetic quality of each image within a portrait dataset. Several papers we researched, such as Automated Aesthetic Analysis of Photographic Images and Assessing the Aesthetic Quality of Photographs Using Generic Image Descriptors, used a binary classification. We implemented a variety of different features drawn from past research, and integrated them into an algorithm that not only classified images in a binary decision of a “good” or “bad” image, but took a relative approach of comparing images within a dataset, which reached a consensus with human judgments for 14 photos out of the top 20 it selected from a total of 102 images. Therefore, we showed that it is feasible to use the combination of few basic features in order to align fairly closely with the subjective nature of humans deciding which images have the highest aesthetic quality. In our user study, we also experienced how it was a tedious and time-consuming task for humans to stack-rank datasets of 50 images, but our algorithm could accomplish the same task within a few seconds. As a result, we met our two main objectives of the project: we developed an algorithm that could estimate human perception of aesthetic quality, and then we used that algorithm to simplify and accelerate the task of selecting the highest-quality images within a large dataset of similar portrait photos.
References:
Aydın, T. O., Smolic, A., Gross, M. (2015, January). Automated Aesthetic Analysis of Photographic Images, in IEEE Transactions on Visualization and Computer Graphics, vol. 21, no. 1, pp. 31-42
Deng, Yubin., Change Loy, Chen., Tang, Xiaoou. (2018, October). Aesthetic-Driven Image Enhancement by Adversarial Learning in MM ‘18: Proceedings of the 26th ACM international conference on Multimedia, pp. 870-878
Grenoble, L. M., Perronnin, F., Csurka, G. (2013, November). Predicting the aesthetic value of an image. United States patent no. US008594385B2.
Ke, Yan., Tang, Xiaoou., Jing, Feng. (2006). “The Design of High-Level Features for Photo Quality Assessment,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), pp. 419-426
L. Marchesotti, F. Perronnin, D. Larlus and G. Csurka, “Assessing the aesthetic quality of photographs using generic image descriptors,” 2011 International Conference on Computer Vision, Barcelona, 2011, pp. 1784-1791, doi: 10.1109/ICCV.2011.6126444.
Obrador, P., Saad, M., Suryanarayan, P., Oliver, N. (2014, February). Method to assess aesthetic quality of photographs. United States patent no. US008660342B2.
Sutherland, A., Rathnavelu, K., Smith, E. (2014, September). Method and system to detect and select best photographs. United States patent no. US008837867B2.